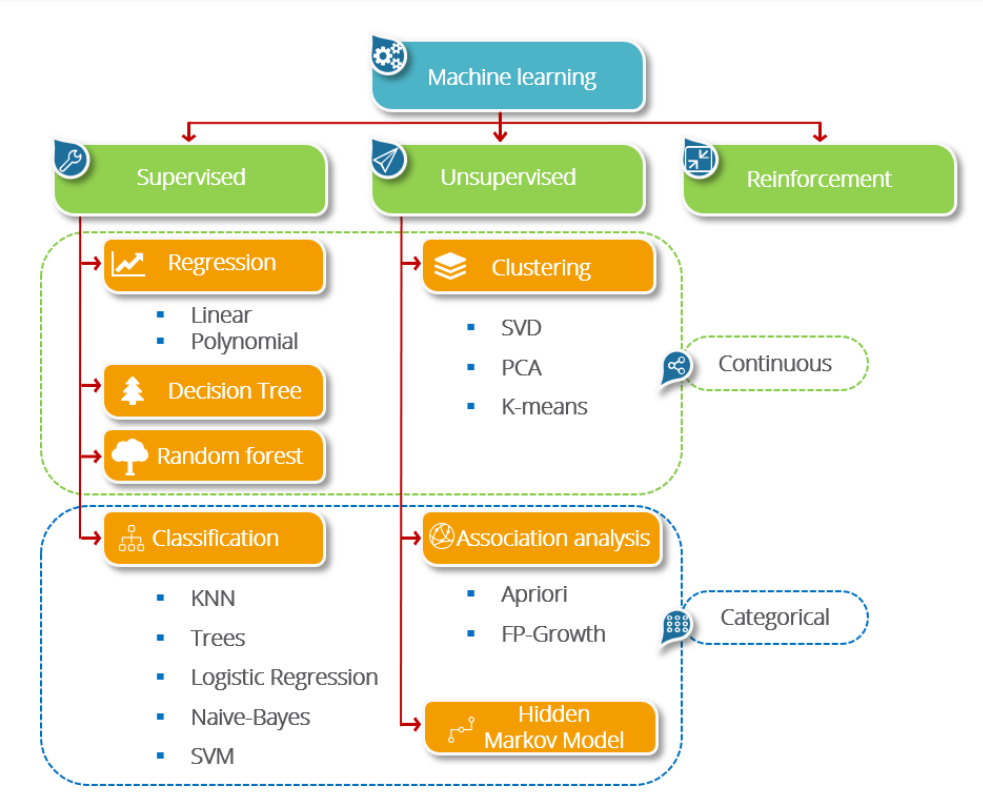
머신러닝은 학습방법에 따라 크게 3가지 종류로 나뉠수 있습니다.
사람이 입력과 출력을 모두 제공하는 지도학습(Supervised Learning), 입력만 제공하는 비지도학습(Unsupervised Learning), 어떤 환경에서 특정목표를 달성하기 위해서 스스로 학습하는 강화학습(Reinforcement Learning)입니다.
현시점에서 활용빈도로 보면 지도학습이 가장 많고, 그 다음이 비지도학습, 마지막은 강화학습이 되겠습니다.

1) 지도학습 (Supervised Learning)
- 지도학습은 가장 많이 활용되는 머신러닝의 종류로 스팸메일 필터링, OCR 문자 인식 등이 이에 해당됩니다. 지도학습은 머신러닝에 입,출력을 모두 제공하여 학습하게 하는 거승로, 일종의 최적 (Optimization) 문제로도 생각을 할 수 있습니다. 이는 지도학습 알고리즘이 주어진 입력값을 분석해 출력값을 만들어내기 위한 최적의 모델을 만들기 때문입니다. 예를 들어, 고양이의 이미지를 구분할 수 있는 머신러닝 프로그램을 개발한다고 가정을 합니다. 지도학습은 입력과 출력을 모두 제공해야 하므로 고양이 사진과 함께 고양이라는 것을 알려주어야 합니다. 고양이가 있는 사진에 '고양이'라는 출력 결과도 같이 제공해야 합니다.
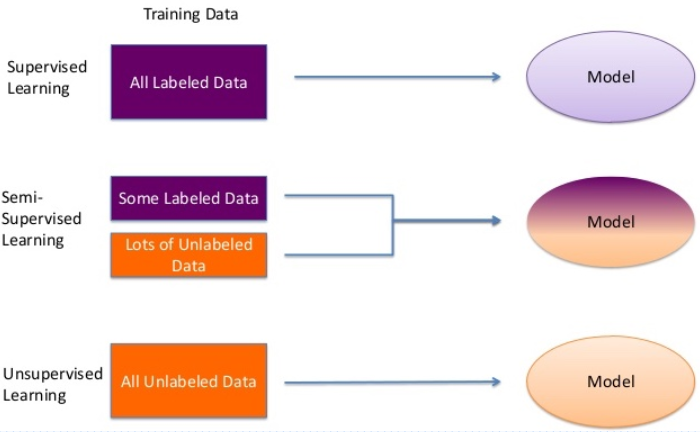
따라서 지도학습에서는 하나의 데이터는 입력과 출력이 같이 묶여있는 튜플(Tuple)형태로 이루어집니다.
2) 비지도학습 (Unsupervised Learning)
- 위에서 설명한 지도학습이 입력을 분석해 출력을 만들어내는 최적화 문제라면 비지도 학습은 입력 데이터의 구조를 파악하거나 관계를 분석하는 방법이라고 할 수 있습니다. 비지도 학습은 '지식 발견 (Knowledge Discovery)'라고도 하는데, 이는 학습결과로 생각하지 못한 지식을 발견하거나 입력 데이터 간의 그룹 또는 특성 들을 발견할 수 있어서입니다.
지도학습과 구분되는 또 하나의 특징은 학습결과에 대한 평가가 힘들다는 점이 있습니다. 이는 학습결과가 명확한 목적, 즉 출력이 없어서 평가기준을 잡을 수 없기 때문입니다. 지도학습에서 데이터를 제공할 때 하나의 데이터마다 입력과 출력이 튜플로 제공되지만, 비지도 학습에서는 출력 없이 입력만 제공됩니다.
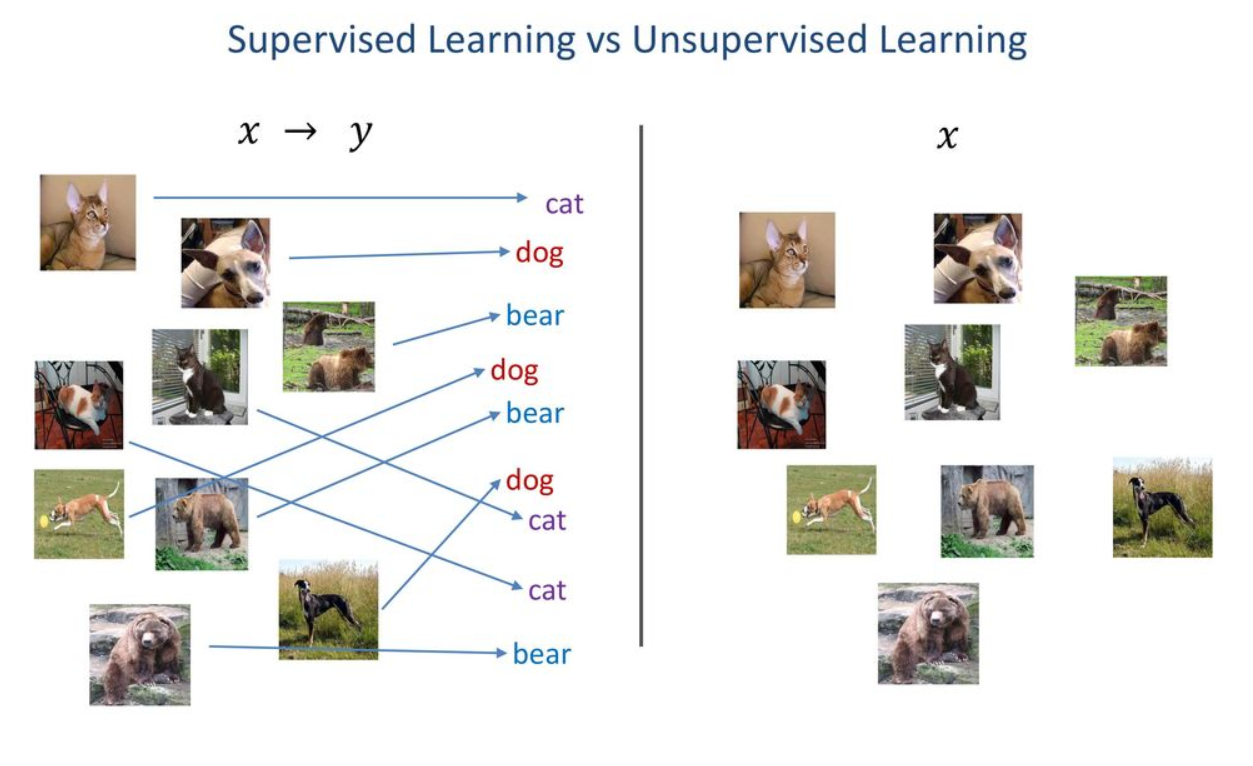
앞의 지도학습에서는 고양이 사진과 이름이 주어졌지만, 다음 그림처럼 비지도학습에서는 이름 없이 고양이 사진만으로 학습이 이루어집니다.

※ 오늘은 '머신러닝의 종류'에 대하여 알아보았습니다.
이 포스트는 학부에서 제공하는 기본적인 강의와 책들을 토대로 알기 쉽게 내용을 작성하였습니다. 하지만 계속 더 유익하고 논문 및 전문 서적을 읽어가며 더 추가돼야 할 내용이 있으면 인공지능, 머신러닝 포스트와 콘텐츠들을 계속 고도화하는 방식으로 진행하려고 합니다.
'데이터 사이언스 > 머신러닝' 카테고리의 다른 글
| [머신러닝 기초] 분류 (Classification) (0) | 2019.10.03 |
|---|---|
| [머신러닝 기초] 회귀 (Regression) (0) | 2019.09.28 |
| [머신러닝 기초] 머신러닝이 할 수 있는 것 (0) | 2019.09.28 |
| [머신러닝 기초] 머신러닝의 장단점 (0) | 2019.09.27 |
| [머신러닝 기초] 머신러닝이란 무엇인가? (0) | 2019.09.27 |