군집화는 데이터를 유사한 특성을 가진 무리(Cluster)로 묶는 것을 의미합니다. 군집화는 비지도 학습에서 사용하는 것으로 출력데이터 없이 입력 데이터만으로 이뤄지며, 일반적으로 데이터의 특성을 파악하거나 이해하기 위해 많이 적용되고 있습니다.
예를 들어, 마케팅 캠페인을 진행하는데 어떤 특성을 가진 사람들이 마케팅 캠페인에 반응하는지를 알고 싶다고 가정을 해봅시다. 마케팅 캠페인을 처음 시행해서 연관성 있는 데이터는 가지고 있지만, 어떤 기준으로 대상자를 선정하는 것이 좋을지 모른다면 이러한 문제를 해결하는 데 군집화가 효과적으로 적용될 수 있습니다.
군집화는 주어진 데이터들의 유사도를 계산해 비슷한 특성이 있다고 판단되는 것끼리 군집으로 분류하는 것으로, 이러한 작업을 효율적으로 할 수 있습니다. 마케팅에 반응한 사람들의 데이터를 모아 군집화를 실시하면 유사한 특성을 가진 사람들을 묶어 몇 개의 군집인지 알 수 있고, 각각의 군집에 속한 사람들의 공통점을 파악하면 원래의 문제인 마케팅에 반응하는 사람들의 유형과 그들의 특성을 발견할 수 있습니다.
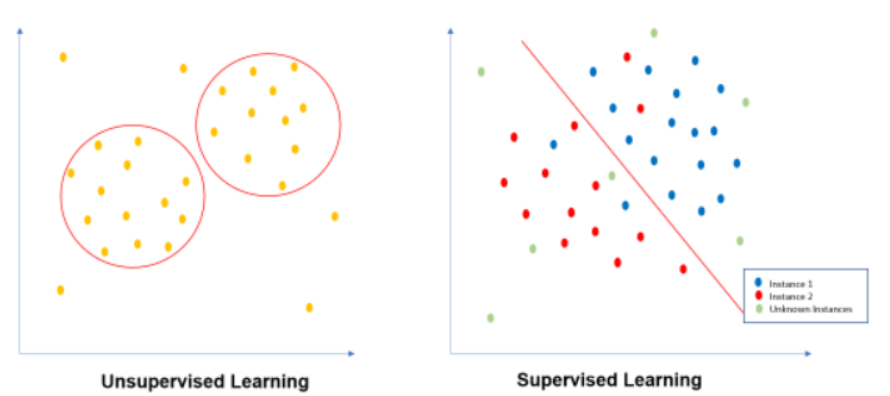
군집화를 실시해 위의 그림과 같은 결과를 얻었다면 잠정적으로 마케팅 캠페인에 반응하는 사람의 군집은 2개가 되므로 이들 군집에 속한 사람들의 특성을 분석하면 됩니다.
군집 문제의 예는 아래와 같습니다.
* 유사한 음악 취향을 가진 사용자를 묶습니다.
* 천문학 데이터를 이용해 유사한 특성을 가진 별을 찾습니다.
* 전자상거래 사용자가 좋아할 만한 물건을 추천합니다.
※ 오늘은 '군집화(Clustering)'에 대하여 알아보았습니다.
이 포스트는 학부에서 제공하는 기본적인 강의와 책들을 토대로 알기 쉽게 내용을 작성하였습니다. 하지만 계속 더 유익하고 논문 및 전문 서적을 읽어가며 더 추가돼야 할 내용이 있으면 인공지능, 머신러닝 포스트와 콘텐츠들을 계속 고도화하는 방식으로 진행하려고 합니다.
#인공지능 #컴퓨터공학 #AI #머신러닝 #Machinelearning #데이터사이언스 #Datascience #군집화 #Clustering
'데이터 사이언스 > 머신러닝' 카테고리의 다른 글
| [머신러닝 기초] 머신러닝 알고리즘 (0) | 2019.10.05 |
|---|---|
| [머신러닝 기초] 분류 (Classification) (0) | 2019.10.03 |
| [머신러닝 기초] 회귀 (Regression) (0) | 2019.09.28 |
| [머신러닝 기초] 머신러닝이 할 수 있는 것 (0) | 2019.09.28 |
| [머신러닝 기초] 머신러닝의 종류 (0) | 2019.09.28 |