
3. 2000년 ~ 2010년 : 통계 기반 머신러닝과 분산 처리 기술의 발전
인공지능 연구는 앞에서 설명한 신경망 외에도 통계 모델링을 중심으로 한 머신러닝 알고리즘이 있습니다. 이 연구는 신경망 연구만큼 주목받지는 않았지만 착실히 발전한 분야입니다. 그리고 컴퓨팅 연산 성능을 개선하는 분산 처리 기술또한 같이 발전하게 됩니다.
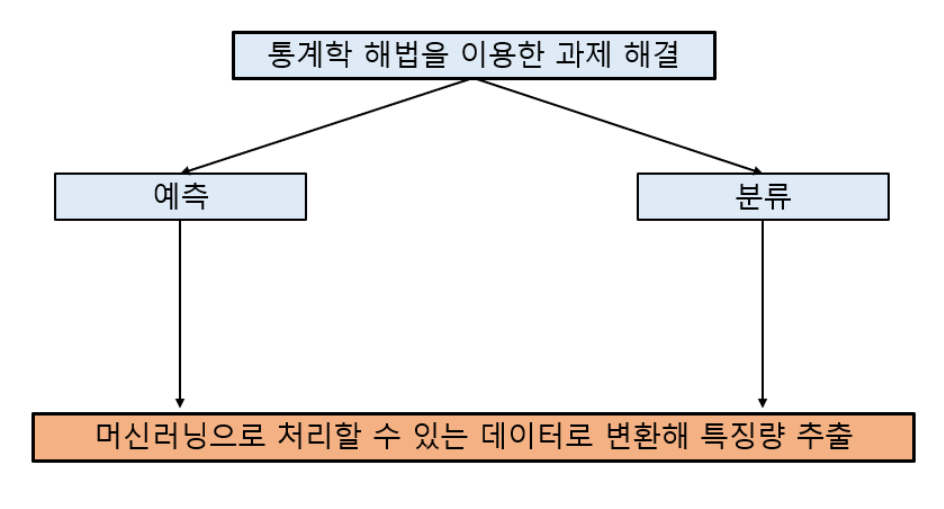
통계를 이용해 문제를 해결하는 방법은 크게 어떤 기준으로 데이터를 나누는 분류(Classification)와 데이터로 앞으로 필요한 결과를 예측(Prediction)으로 나눌 수 있습니다. 통계 기반 머신러닝은 이 분류와 예측을 프로그램화한 것으로 분류와 예측을 주어진 데이터를 자동으로 계산해 특징량 (feature)을 추출합니다.
추출한 특징량은 구성 요소와 기여도를 사람이 직접 확인하는 등의 추가 분석을 거쳐 통계 모델링을 하면 자동 처리에 이용할 수 있습니다.
이러한 머신러닝 시스템의 대표적인 예로는 추천 엔진과 로그 데이터, 온라인 데이터를 이용한 이상 탐지 시스템 등이 있습니다.

통계 기반 머신러닝 연구가 활발해진 계기는 1990년대 베이즈 정리를 출발점에 둔 베이즈 통계학의 재조명입니다. 앨런 E. 겔펀드(Alan E. Gelfand)와 에이드리언 F. M. 스미스 (Adrian F. M. Smith)는 1990년 [Sampling-Based Approaches to Calculating Marginal Densities] 에서 현대 베이즈 통계 계산의 핵심이 되는 마르코프 연쇄 몬테카를로 방법의 초기 형태를 제안했습니다. 이는 현재 우리가 연구하는 머신러닝 알고리즘의 기반이 되기도 했습니다.
2000년대에는 베이즈 필터를 이용한 머신러닝 시스템을 도입했습니다. 이 시스템을 이용한 대표적인 예로는 이메일 스팸 판정, 음성 입력 시스템의 노이즈 줄이기, 발음 식별 처리 등이 있습니다.
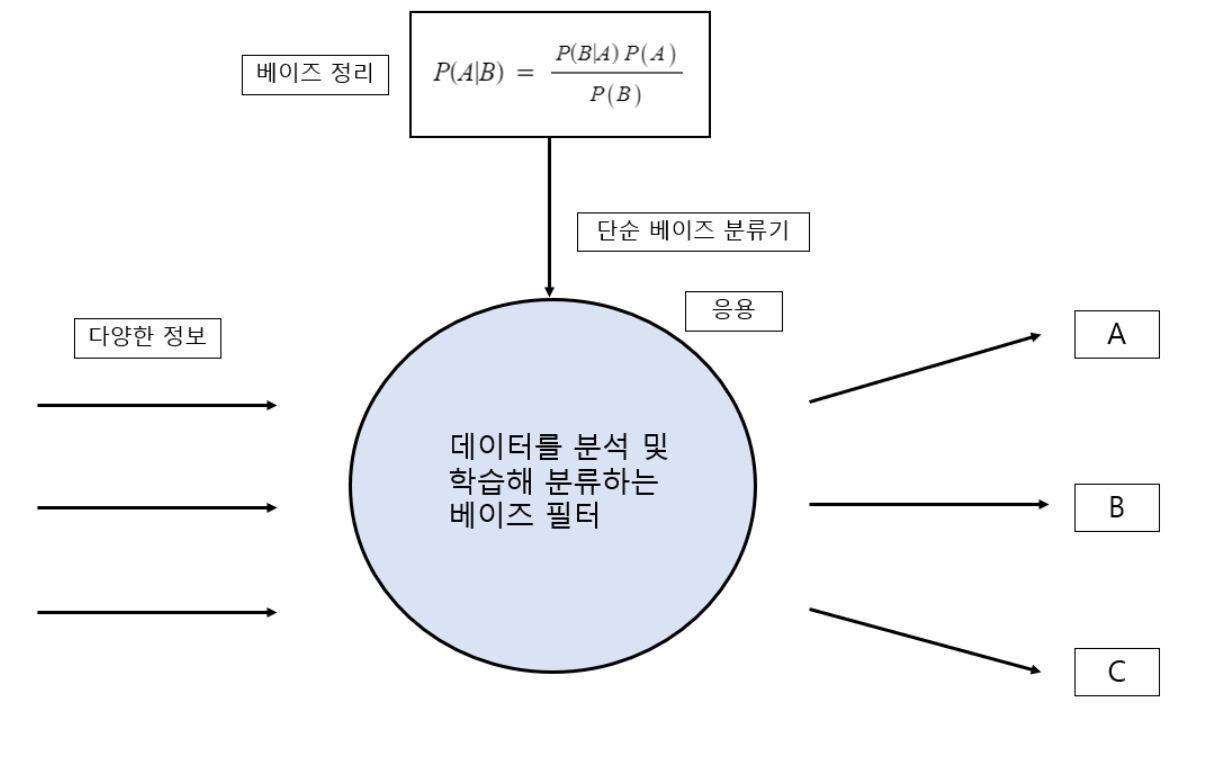
※ 베이즈 정리
토머스 베이즈가 최초로 정리했고, 피에르시몽 라플라스가 확립했습니다.
조건은 다음과 같습니다.
- 사건 A가 일어날 확률 P(A)
- 사건 B가 일어날 확률 P(B)
- 사건 A가 일어났을때 사건 B가 함께 일어날 조건부 확률 P(B|A)
- 사건 B가 일어났을때 사건 A가 함께 일어날 조건부 확률 P(A|B)

'데이터 사이언스 > 인공지능 기초' 카테고리의 다른 글
| [인공지능 기초] 분산 처리 기술 발전 (0) | 2019.10.04 |
|---|---|
| [인공지능 기초] 인공지능의 발전 흐름 part 2 (0) | 2019.09.29 |
| [인공지능 기초] 인공지능의 발전 흐름 part 1 (0) | 2019.09.29 |
| [인공지능 기초] 'AI' (Artificial Intelligence) 인공지능 이름을 지은 사람 (0) | 2019.09.28 |
| [인공지능 기초] 튜링 테스트 (Turing Test) (0) | 2019.09.23 |