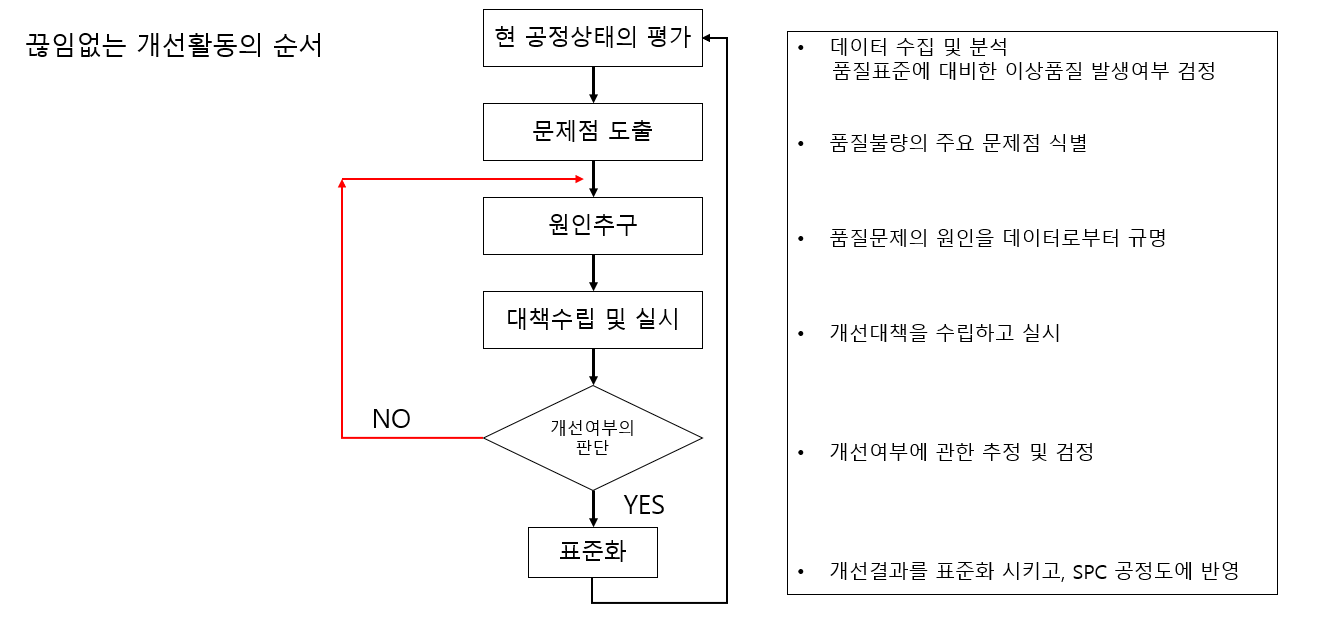
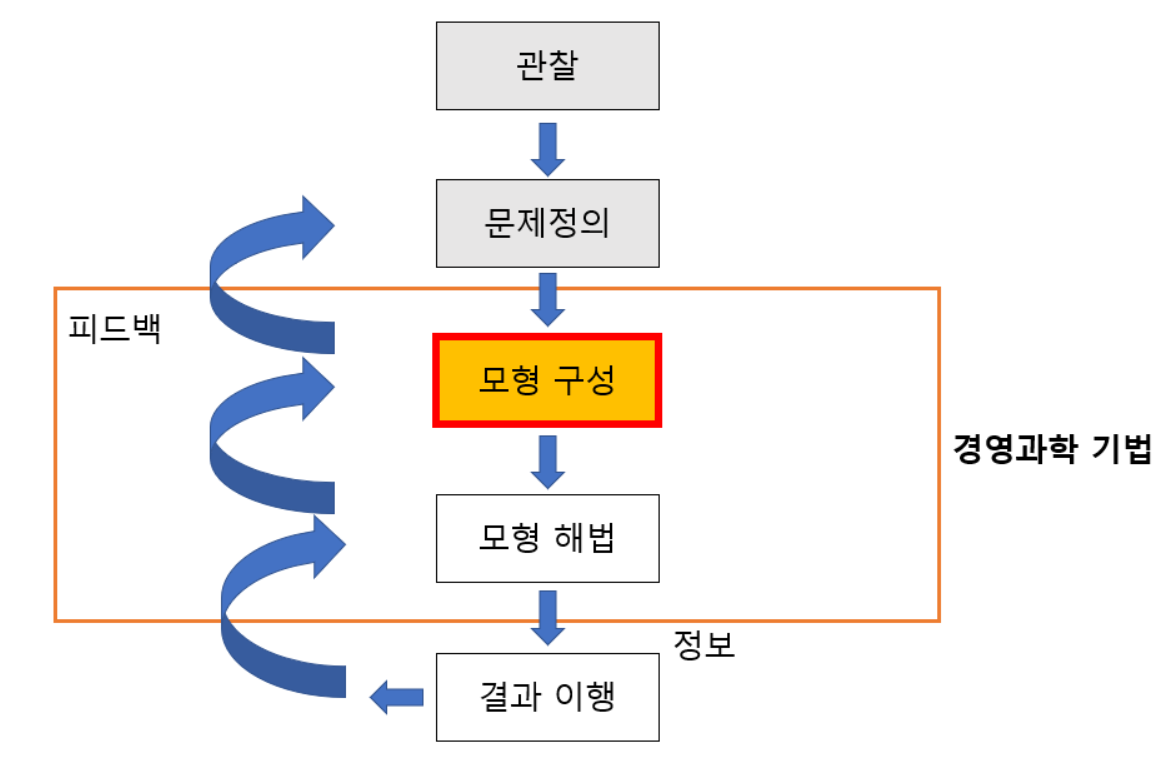
실행계획법의 기본 원리는 반복화, 랜덤화, 블록화입니다. 이를 통하여 실험의 정도 향상과 실험 환경의 동질성을 확보할 수 있으며, 이러한 원리들은 실험계획에서 통계적인 방법들을 사용할 수 있게 해주는 바탕이 됩니다.
1. 반복화(replication)
특정 조건에서 1회만의 실험으로 얻어진 데이터는 신뢰성이 떨어집니다. 즉, 실험이 정확하게 되었는지를 확신할 수 없게 됩니다. 따라서 각 실험 조건을 반복하여 실험함으로써 데이터의 재현성을 확보하는 것이 일반적입니다.
첫째, 실험오차의 추정을 가능하게 해주며, 이 오차의 추정치는 실험에서 관측된 데이터의 차이가 통계적으로 유연한지를 결정하는 가장 기본적인 단위가 됩니다.
둘째, 만약 실험에서 취해진 어떤 인자의 효과를 추정하기 위하여 표본 평균이 사용된다면 반복은 이 인자의 효과에 대해서 보다 정밀한 추정치를 제공해 줍니다.
일반적으로 실험을 반복하게 되면 오차항의 자유도를 크게 해 줄 수 있어 오차 분산의 정도가 좋게 추정되며, 인자조합의 효과(교호작용)를 분리하여 구할 수 있을 뿐만 아니라, 실험의 재현성과 관리 상태를 검토할 수 있습니다.
한편, 반복이 이루어지지 않는 실험의 경우는 오차에 대한 추정이 불가능해지고 분산분석이 어렵게 됩니다. 이러한 경우를 포화된 모형(saturated model)이라고 하는데 가급적 피하는 것이 좋습니다.
2. 랜덤화(randomization)
실험을 계획할 때에는 통제가 가능한 요인들을 주인자로 채택하고, 통제가 불가능한 요인들은 잡음인자로 처리하여 이 요인들의 효과가 비교. 분석하고자 하는 각 처리(인자 수준의 조합)의 효과에 고르게 나타나게 해야 합니다.
이렇게 잡음인자들의 효과를 평준화하여 특정 처리에 치우침이 생기지 않게 하기 위해서 사용하는 방법이 바로 실험 순서의 랜덤화입니다.
랜덤화란 실험 재료의 배치와 각 실험의 시행 순서가 무작위적으로 결정되는 것을 의미하는데 (엄밀하게 말하면 실험의 각 처리가 동일한 확률로 배당됨을 뜻합니다.) 이와 같은 랜덤화는 통계적 분석을 용이하게 해줍니다. 예를 들면, 일반적으로 분산분석에서 사용하는 F 검정은 특성치 또는 오차에 대하여 정규성과 독립성을 가정하고 있는데 랜덤한 실험은 이러한 분석의 통계적 근거를 제공해줍니다.
3. 블록화(blocking / local control)
실험에서 얻어진 데이터의 정도, 또는 분석력을 높이기 위해서는 잡음으로 처리한 요인들의 효과(오차)가 최소화되도록 해야 하는데, 실험 전체를 단순한 랜덤화에 의해서 평준화하면 오차 변동이 커져서 정도 높은 분석을 할 수 없습니다. 즉, 단순한 랜덤화로는 실험 환경의 동질성을 확보하는 데 한계가 있다는 것입니다.
따라서 실험환경을 시간적 또는 공간적으로 분할하고 층별하여 블록으로 만들면 각 블록 내에서의 데이터의 동질성이 확보되고 실험 환경이 균일해져서 실험의 정도를 높일 수 있습니다. 이때 블록을 하나의 인자로 잡아주게 되면 블록간의 효과를 분리하여 식별할 수 있게 되므로 오차 변동이 그 만큼 작아집니다. 이러한 원리를 층별 또는 소분의 원리라고도 하며, 난괴법이 대표적입니다.
이외에도 실험의 효율을 높이기 위한 방법으로 다음의 2가지 원리가 많이 사용됩니다.
A) 교락화(Compounding)
일반적으로 실험에서 다루어지는 인자의 수가 많아질수록 각 인자들간의 교호작용을 포함한 모든 요인들의 효과를 알아내기 위해서는 실험 횟수가 상당히 커져서 시간과 비용이 많이 들어가게 됩니다. 그러나 특정 인자의 효과나 교호작용 등이 실험의 목적에 부적합하거나 의미가 없어서 검출할 필요가 없을 때에는 이러한 효과들이 블록의 효과와 겹쳐서 나타나도록 실험을 계획하면 실험의 횟수를 줄일 수 있습니다.
B) 직교화(Orthogonality)
어떤 관측된 변량, 또는 이들의 선형결합이 통계적으로 서로 독립일 때, 이들은 서로 직교한다고 말하는데, 요인간에 직교성을 갖도록 실험을 계획하여 데이터를 구하면 동일한 실험 횟수라도 검출력이 더 놓은 검정을 할 수 있고, 더 정도가 높은 추정을 할 수 있다고 알려져 있습니다.
이러한 성질을 만족하도록 고안된 표가 직교배열표이며, 이 표를 이용하면 기술적으로 무시될 수 있는 교호작용 등을 손쉽게 주효과와 교락시켜 실험의 크기를 크게 줄일 수 있어서 효율적인 실험을 설계할 수 있습니다.