분류는 단어가 의미하는 대로 데이터를 나누는 것을 의미합니다. 분류에 대한 이해를 하기 위해서 아이리스의 예제를 한번 살펴보겠습니다.
꽃잎의 너비와 높이 데이터를 이용해 주어진 아이리스가 Sentosa, Virginica, Versicolor 3 종류 중 어떤 품중에 속하는지를 판별해야 한다고 가정을 해봅시다. 이 문제는 저번 포스트에서 설명한 회귀와는 다르게 어떤 값을 예측하는 것이 아니고 어떤 종류에 속하는지를 파악하는 문제입니다. 회귀 문제와 마찬가지로 분류 역시 산점도를 그려 아이리스 품종별로 꽃잎의 너비와 높이가 어떤 관계가 있는지를 파악해야 합니다.

위의 그림을 살펴보면 Sentosa 품종은 화면에 네모로 왼쪽 아래에 위치하고, Virginica는 원으로 오른쪽 위에 위치하며, 그 중간에 삼각형으로 Versicolor 품종이 있음을 알 수 있습니다. 해결하려는 문제는 주어진 꽃잎의 너비와 데이터만으로 어떤 품종인지를 파악하는 것이므로 3가지 품종을 구분하는 방법이 필요합니다. 만약 어떤 모델이 있고 이 모델을 이용해 꽃잎의 너비와 높이에 따라 품종을 구분할 수 있게 된다면 새로운 데이터로 너비와 높이 데이터만을 입력해도 품종을 구분할 수 있습니다.
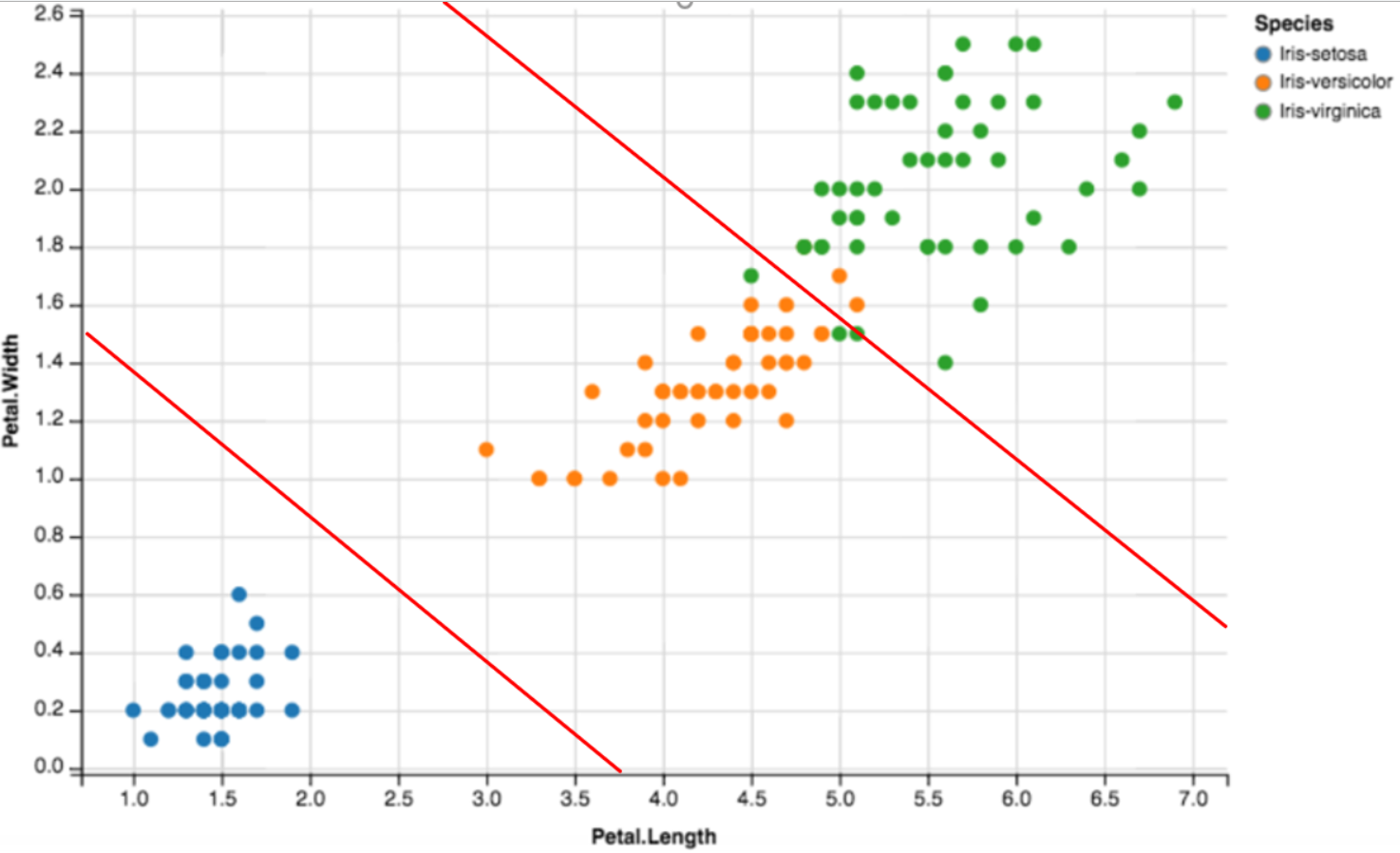
위의 그림과 같이 2개의 선을 이용해 Sentosa, Virginica, Versicolor로 영역을 나눈 다음 새롭게 주어진 데이터가 3개의 영역 중 어디에 위치하는지를 안다면 자연스럽게 아이리스 품종을 분류할 수 있습니다. 따라서 분류는 주어진 데이터들을 이용해 아이리스를 잘 구분 지을 수 있는 2개의 'Y = aX + b ' 를 찾는 것이라 할 수 있습니다.
분류는 이와 같은 과정을 거쳐 데이터를 구분할 수 있게 하는 것으로 머신러닝에서 매우 광범위하게 사용되고 있기도 합니다. 회귀는 연속적인 데이터(Continuous Data)에 적용할 수 있지만, 분류는 범주형 데이터 (Categorical Data)에 적용할 수 있습니다.
분류 문제의 예는 아래와 같습니다.
* 스팸메일 분류
* 이미지 인식
* 음성 인식
* 질병 발생 여부 판별
※ 오늘은 '분류(Classification)'에 대하여 알아보았습니다.
이 포스트는 학부에서 제공하는 기본적인 강의와 책들을 토대로 알기 쉽게 내용을 작성하였습니다. 하지만 계속 더 유익하고 논문 및 전문 서적을 읽어가며 더 추가돼야 할 내용이 있으면 인공지능, 머신러닝 포스트와 콘텐츠들을 계속 고도화하는 방식으로 진행하려고 합니다.
'데이터 사이언스 > 머신러닝' 카테고리의 다른 글
| [머신러닝 기초] 머신러닝 알고리즘 (0) | 2019.10.05 |
|---|---|
| [머신러닝 기초] 군집화 (Clustering) (0) | 2019.10.03 |
| [머신러닝 기초] 회귀 (Regression) (0) | 2019.09.28 |
| [머신러닝 기초] 머신러닝이 할 수 있는 것 (0) | 2019.09.28 |
| [머신러닝 기초] 머신러닝의 종류 (0) | 2019.09.28 |