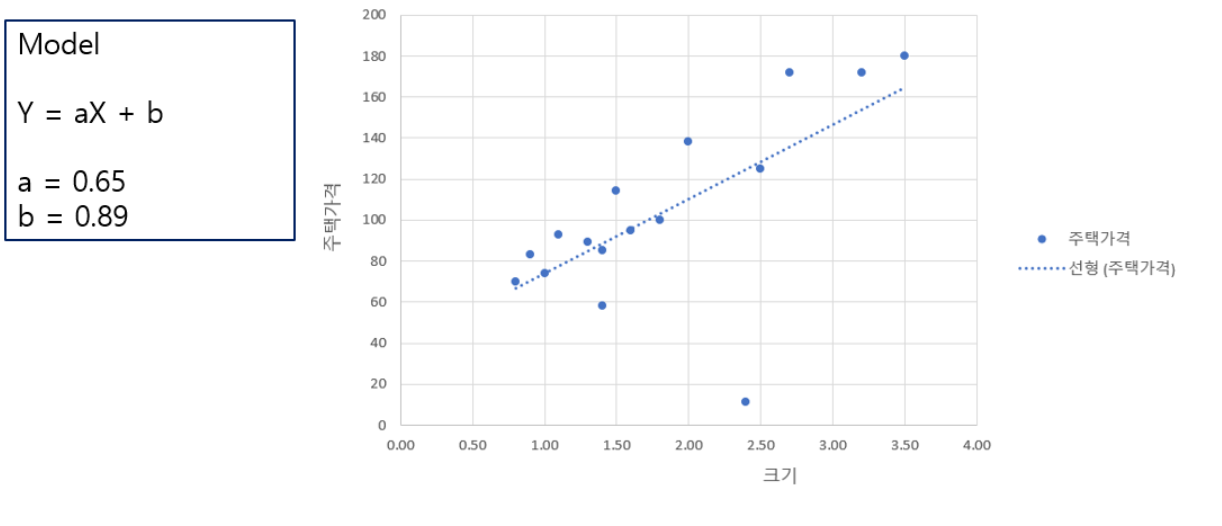
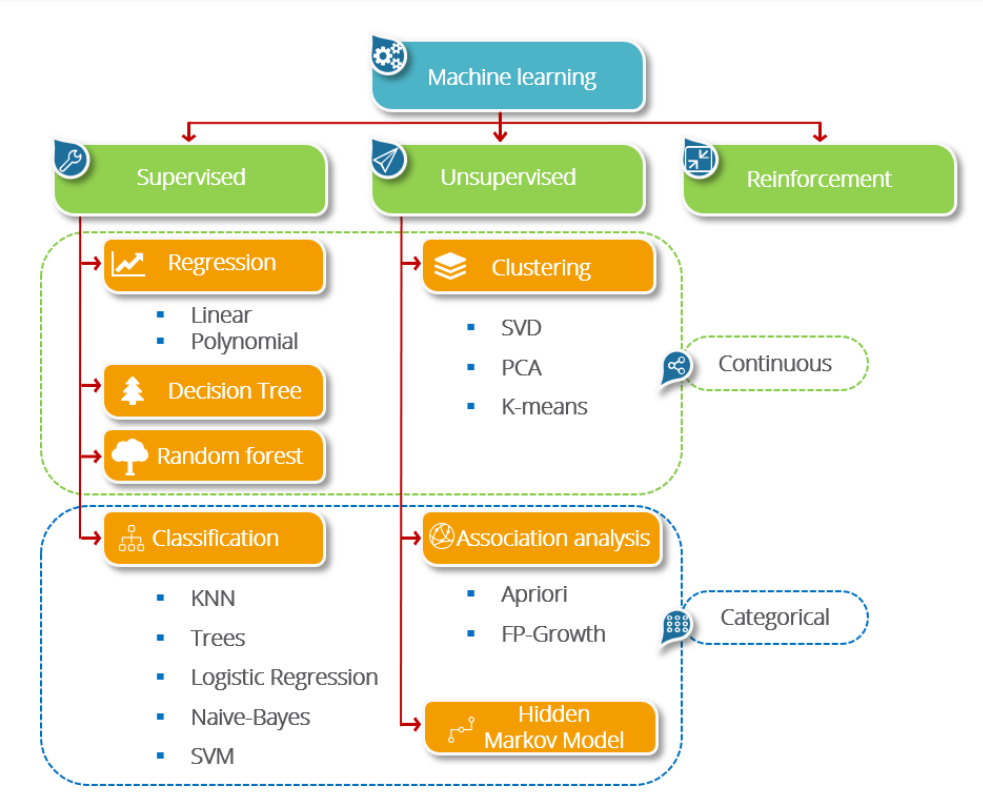
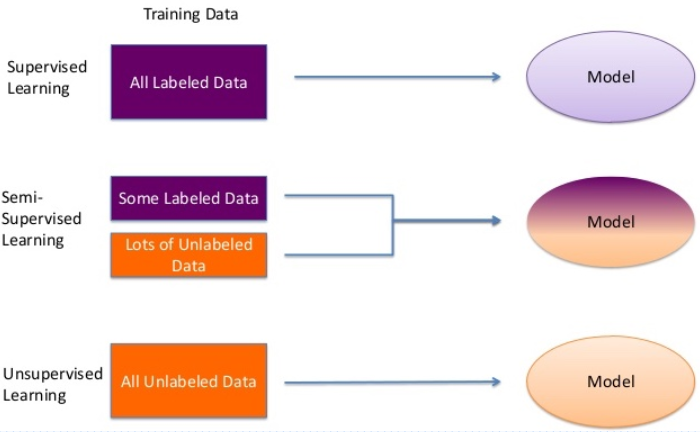
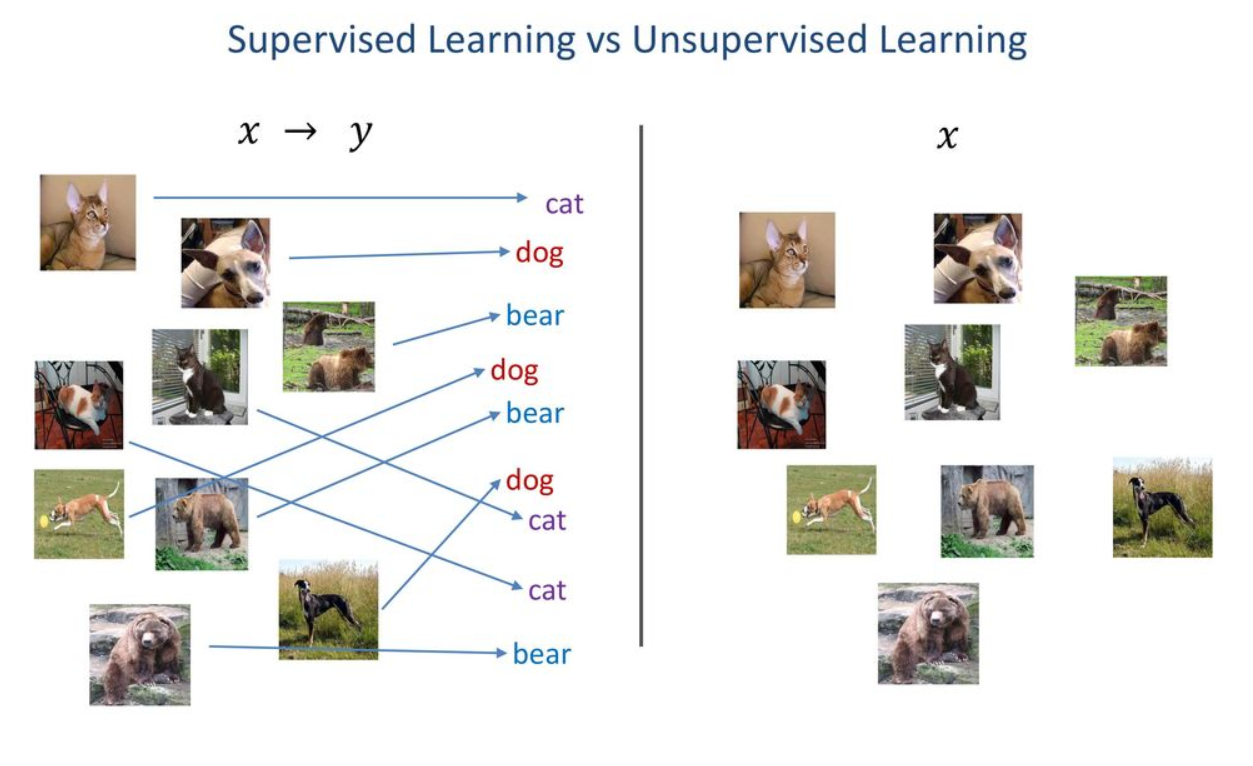
알고리즘을 이해하기 어려운 이유는 컴퓨터가 이해하는 명령을 표현하기 위한 특별한 표기법을 사용하기 때문입니다. 알고리즘은 프로그래밍 언어와 독립적이므로 알고리즘을 구성하는 문장들을 표현하기 위해서는 별도의 표기법이 필요합니다.
혼자만 이해할 수 있는 방법으로 알고리즘을 나타내는 것도 방법 중 하나이지만, 기록해두었던 내용을 시간이 흐른 후 다시 보면 기억이 나지 않는 불상사가 일어날 수도 있습니다. 프로그래밍 경험이 쌓이면 알고리즘을 생각하면서 생각한 내용을 바로 프로그래밍 언어로 나타낼 수 있습니다. 하지만 프로그램을 처음 배울 때는 바로 효과가 나타나지 않습니다. 따라서 먼저 알고리즘을 표준화하는 방법을 이용하여 기술하고, 이를 프로그래밍 언어를 사용하여 구현하는 하향식으로 프로그램을 작성하는 것이 바람직합니다.
알고리즘을 나타내는 표준화된 방법에는 여러 가지가 있지만, 알고리즘은 궁극적으로 프로그래밍 언어로 표현되어야 하므로 알고리즘 표현 방법과 프로그래밍 언어는 떼려야 뗄 수 없는 관계에 있습니다. 일상적인 언어를 사용한 문장의 나열로 나타내는 방법도 알고리즘을 기술하는 방법 중 한 가지이며, 이를 '의사 코드(pseudo code)'라고 합니다. 하지만 프로그램을 염두에 둔 의사 코드는 일상적인 언어가 아니라 프로그래밍 언어에서 사용되는 간단한 영어 단어와 기호를 사용하여 컴퓨터가 이해할 수 있는 문장으로 알고리즘을 표현합니다.

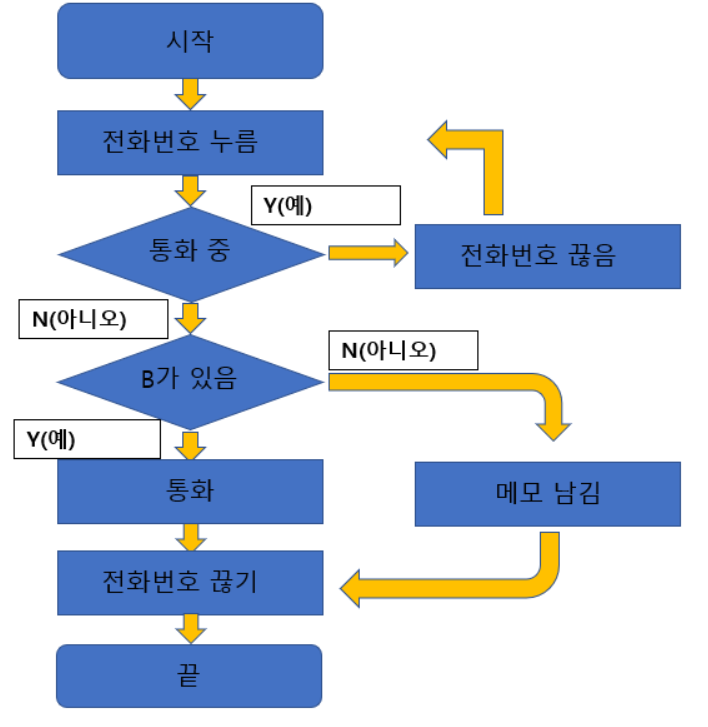
알고리즘을 표현하는 또 다른 방법은 문제 해결의 순서와 흐름을 약속된 기호로 이용하여 그림으로 나타내는 방법으로, 이를 흐름도(flowchart, 또는 순서도)라고 부릅니다. 흐름도는 영어 단어 대신 시각적인 기호를 사용하므로 알고리즘을 직관적으로 이해할 수 있다는 장점이 있습니다. 하지만 복잡한 알고리즘의 경우, 한 페이지 내에 알고리즘을 모두 표현할 수 없고, 그림으로 나타내기가 번거로운 단점도 있습니다. 이러한 단점으로 인해 최근 흐름도를 많이 사용하지는 않지만 프로그래밍을 처음 접하는 경우에는 흐름도가 의사 코드에 비해 알고리즘을 이해하고 작성하기에는 더 쉬운 방법입니다.
※ 오늘은 C언어 프로그래밍에서 '알고리즘을 이해하는 법'에 대하여 알아보았습니다.
이 포스트는 학부에서 제공하는 기본적인 컴퓨터 공학 강의와 책들을 토대로 알기 쉽게 내용을 작성하였습니다. 하지만 계속 더 유익하고 논문 및 전문 서적을 읽어가며 더 추가돼야 할 내용이 있으면 C 언어 프로그래밍 포스트와 콘텐츠들을 계속 고도화하는 방식으로 진행하려고 합니다.
#컴퓨터공학 #C언어 #C언어프로그래밍 #프로그램 #알고리즘 #컴퓨터의문제해결 #프로그래밍언어 #공대공부 #알고리즘이해 #흐름도 #flowchart #순서도 #의사코드
'프로그래밍 > C 언어' 카테고리의 다른 글
| [C언어] '흐름도' 알고리즘을 표현하는 도구 2 (0) | 2019.10.03 |
|---|---|
| [C언어] '흐름도' 알고리즘을 표현하는 도구 (0) | 2019.09.30 |
| [C언어] 일상생활에서 알고리즘 적용 (0) | 2019.09.29 |
| [C 언어] 최초의 알고리즘 (0) | 2019.09.28 |
| [C언어] C언어 프로그램의 Key, 알고리즘 (0) | 2019.09.28 |