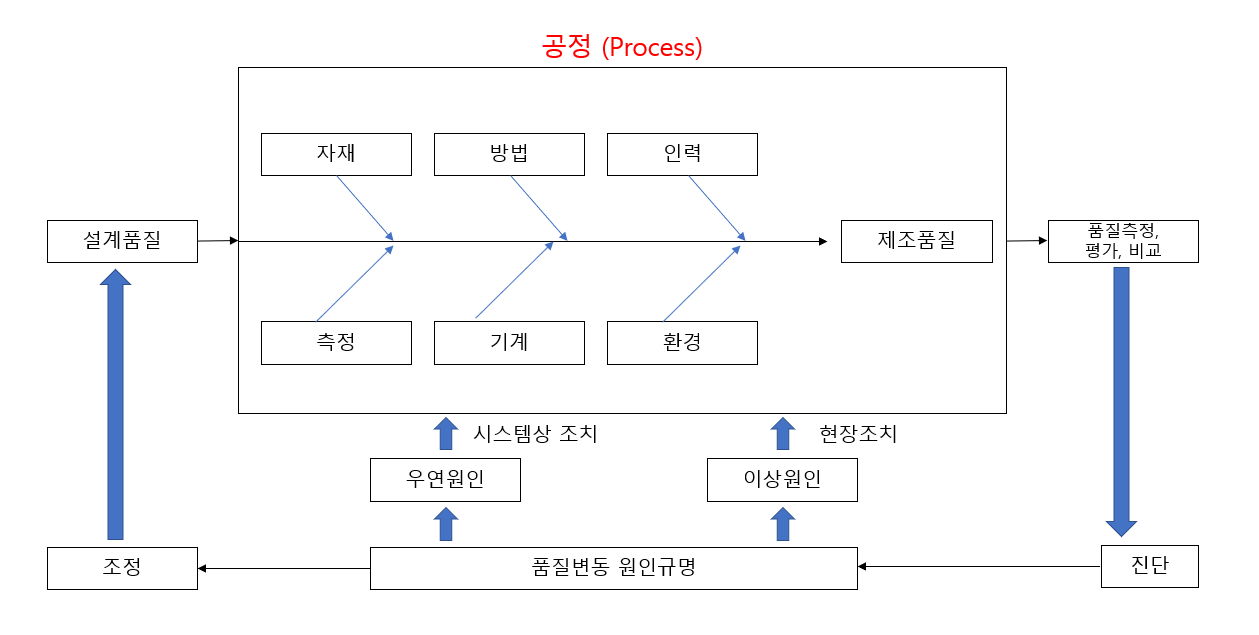
SPC 운영의 시작은 판매부서(영업부서)에서 얻을 수 있는 소비자 요구 품질을 정확히 확보하는 데서부터 시작됩니다. 이 요구 품질의 기초 위에 품질기능전개(QFD: quality function deployment) 등을 통하여 만들려고 하는 제품의 품질특성 기준이 설정됩니다.
그리고 이 기준 위에 공정 간 반제품의 품질특성 기준과 각 공정의 관리 항목 설정이 이루어지며, 이와 같은 작업은 SPC 주관부서에서 생산부서와 협조하여 작성하여야 합니다. SPC 주관부서에서는 공정관리가 용이하도록 SPC 공정도를 작성하는 것이 바람직합니다.
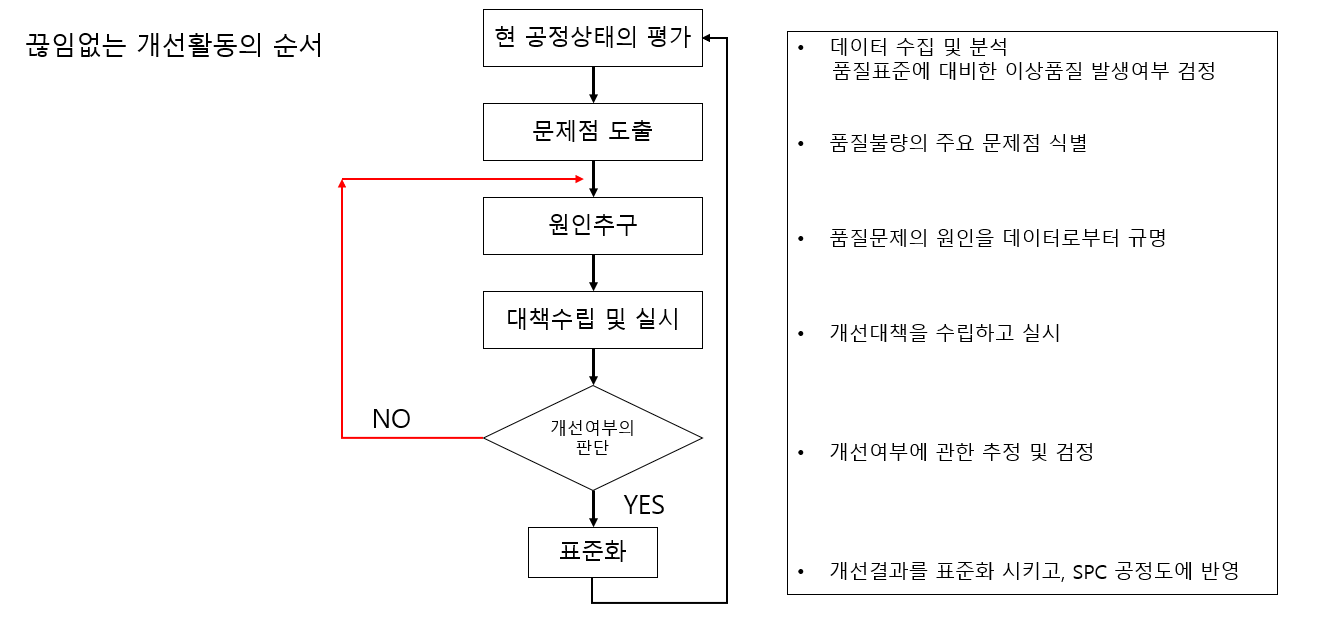
SPC 공정도에 의하여 생산부서의 담당 사원은 SPC 유지 활동을 시행해야 하며, 이때 중점 관리 항목에 의하여 관리하여 주는 것이 바람직합니다. SPC의 유지 활동 중에 공정이 관리 상태라고 판정되면, 공정능력을 산출하여 공정능력이 충분한가를 판단할 필요가 있습니다. 충분하면 계속적인 SPC 활동을 벌어야 합니다.
개선한 결과가 좋으면 이를 표준화 시킨 후에 SPC 유지 활동으로 돌아가나, 개선한 결과가 미흡하면, 이를 중요 품질 문제로 등록한 후에 소집단(품질분임조, 품질 개선팀) 활동을 통하여 근본적인 개선활동을 벌어야 합니다.
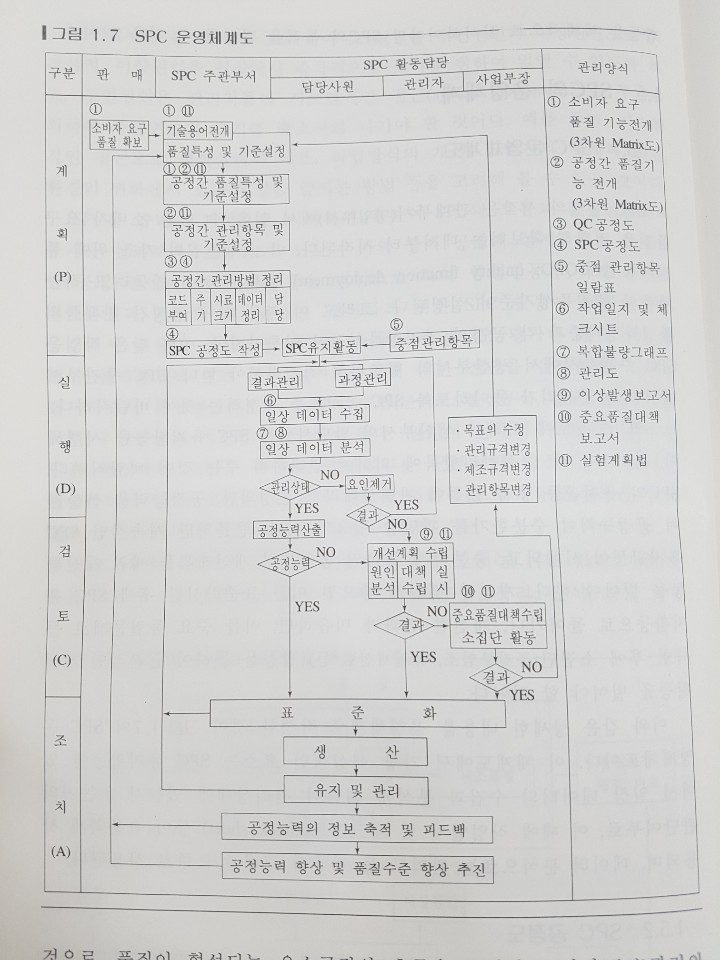
이와 같은 상세한 내용을 운영체계로 작성한 것이 SPC 운영체계도입니다. 이 체계도에서 가장 핵심적인 요소는 SPC 유지 활동에 있어서 일상 데이터의 수집과 분석에 의하여 관리 상태에 있는가 없는가의 판단 여부로, 이때에 작업 일지 및 체크시트(check sheet) 등이 유용하게 사용되며, 데이터 분석으로는 관리도 등 각종 그래프가 주로 사용됩니다.
'산업공학 > 통계적 공정관리' 카테고리의 다른 글
| [통계적 공정관리] SPC와 SQC의 차이점 (0) | 2019.10.21 |
|---|---|
| [통계적 공정관리] 공정관리 시스템과 SPC (0) | 2019.10.21 |
| [통계적 공정관리] SPC의 적: 품질변동 (0) | 2019.10.21 |
| [통계적 공정관리] SPC의 목표 (0) | 2019.10.21 |
| [통계적 공정관리] SPC의 정의 (0) | 2019.10.21 |