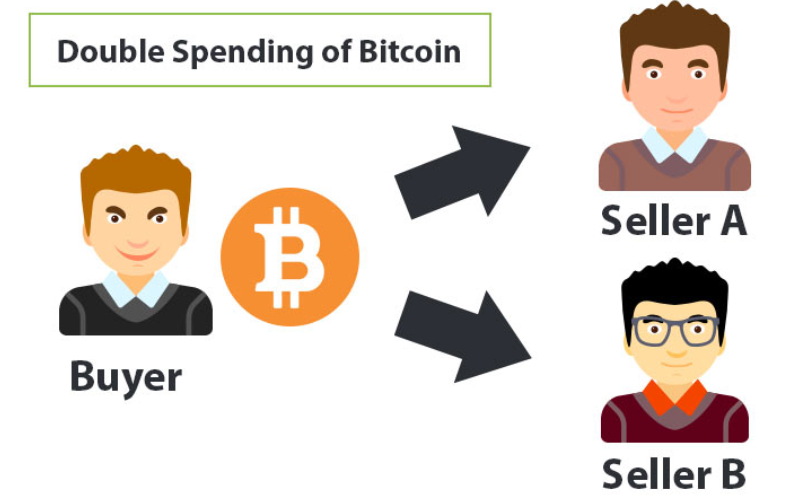
1) 이중 지불 (Double Spending)
- 단일 화폐 단위가 두 번(이중) 결제되는 것.
은행의 경우에는 중앙제어 시스템이 있기 때문에 거래 요청이 발생한 순서대로 거래를 진행하면 이중 지불 문제가 발생할 수 없습니다. 하지만 블록체인은 작업 증명 방식의 합의 알고리즘을 이용하여 이중 지불 문제를 해결하였습니다.

2) 작업 증명 (Proof of Work - PoW)
- P2P(Peer-to-Peer) 네트워크에서 일정 시간 또는 비용을 들여 수행된 컴퓨터 연산 작업을 신뢰하기 위해 참여 당사자 간에 간단히 검증하는 방식, 또는 블록체인에서 정보를 논스(Nonce)값과 해시(Hash) 알고리즘을 적용시켜 설정된 크기의 해시보다 작은 값을 도출하는 과정으로, 새로운 블록을 블록체인에 추가하는 작업을 완료했음을 증명하는 방법입니다.
3) 지분 증명 (Proof of State - PoS)
- 알고리즘의 한 형태로서 이를 통해 암호화폐, 블록체인 네트워크가 분산화된 합의를 얻는 것 지분 증명 기반 화폐는 작업 증명 알고리즘 기반 화폐에 비해 에너지(예: 전기 에너지) 사용 측면에서 더 효율적입니다.

출처: 딜로이트
4) 스마트 컨트랙트 (Smart Contract)
- 디지털로 계약서 작성, 제3자 없이 정해진 대로 스스로 조건이 실행되는 계약입니다.
a) 블록체인에 계약서를 작성하여, 특정 조건 만족 시 계약 내용 실행
b) 대표적 예로 이더리움, 개발 중인 많은 코인들이 스마트 컨트랙트(Smart Contract)를 지원하고 있습니다.


5) P2P (Peer to Peer)
- 인터넷에 연결해 개인들이 각자 보유하고 있는 파일 등을 공유하여 원하는 파일을 다운로드하는 방식, 일반적인 인터넷 자료실이 특정 서버(대형 컴퓨터)를 통해 불특정 다수가 올린 자료를 다시 불특정 가수가 내려받는 형태인데 반해 P2P(Peer to Peer)는 인터넷이 접속한 네티즌 개개인의 PC를 직접 검색, 저장된 자료를 1 대 1로 주고받는 방식입니다.
#핀테크 #컴퓨터공학 #블록체인 #블록체인기초용어 #해시함수 #노드 #분산원장 #데이터위변조방지 #거래기록암호화 #P2P #스마트컨트렉트 #이중지불
'핀테크 > 블록체인' 카테고리의 다른 글
| [블록체인] 블록체인 1.0 (블록체인의 등장) (0) | 2019.10.27 |
|---|---|
| [블록체인] 기본 용어 정리 1 (0) | 2019.10.09 |